What is a Compiler?
Compilers use is ubiquitous in the software world. Any piece of software that is written uses a compiler of some sort. But what exactly is a compiler and how does a compiler work? Let’s explore this at a high level in this post.
Basic job of a compilers is to transform from one (source) language to another (target) language.
Why do we need a compiler?
Computers only understand machine language (0s and 1s) which is almost impossible for anyone to directly write in. Each microprocessor comes up with its own instruction set language called assembly language and an assembler which converts assembly code into native machine language. Assembly language though not as low level as machine language but still very difficult to write by hand. So we have high level languages (e.g. Python, C, Java etc.) that are human readable but we need a translator to translate them to assembly language (that can be translated to native machine language by the assembler). Compiler is such a translator.
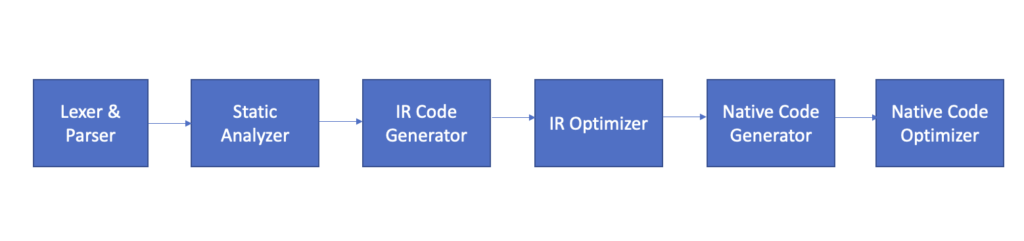
Basic compiler pipeline and how does a compiler work?
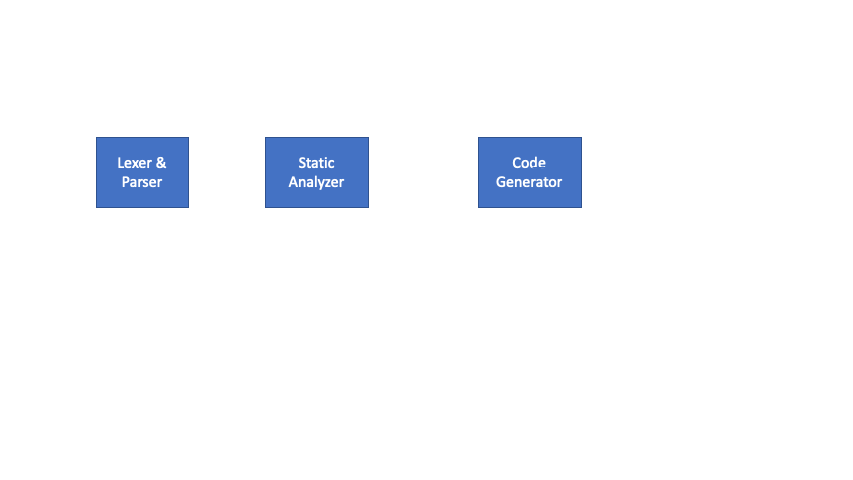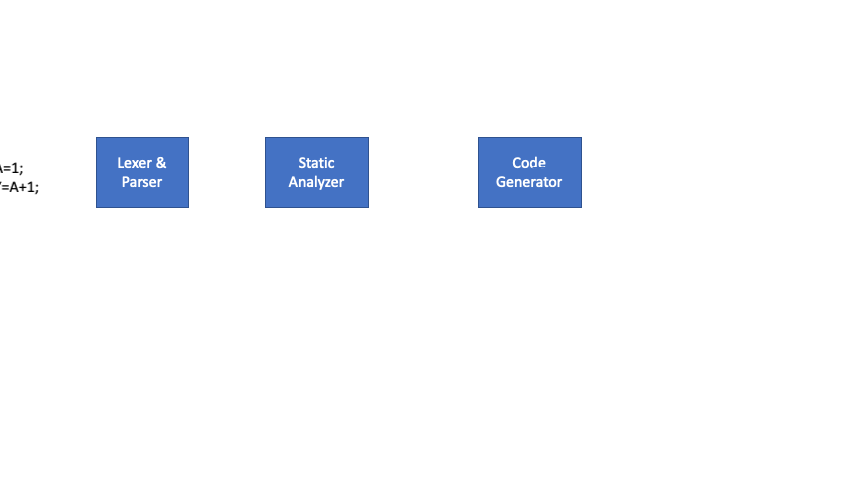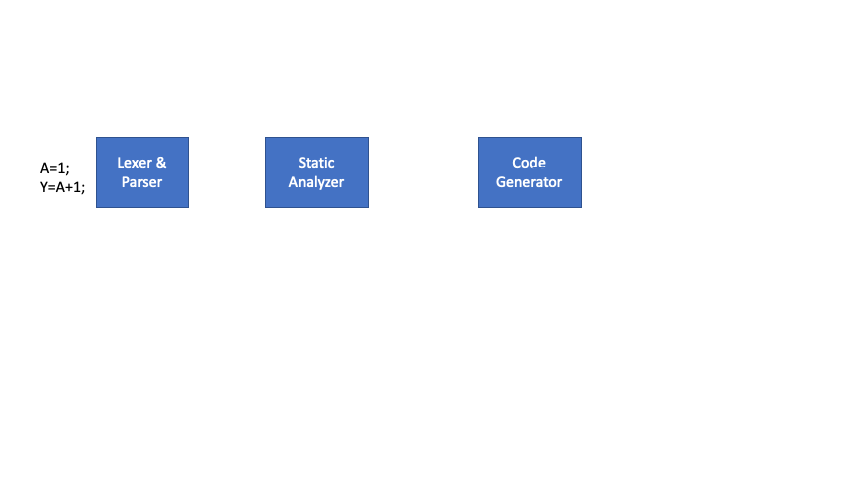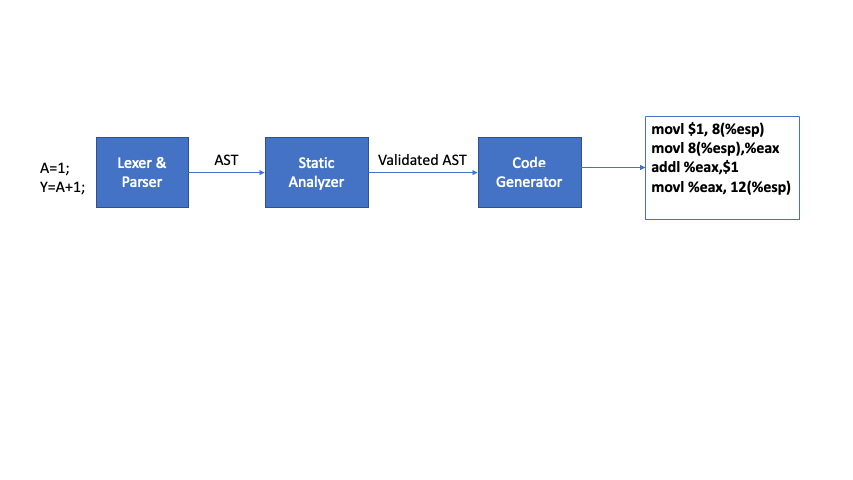
At a high level a compiler consists of 5 components namely Lexer, Parser, Static Analyzer, Code Generator, Optimizer. Typically these components are separate and modular but they can be combined or sub-divided into smaller components in specific compiler implementations

Each of these sections will require multiple long posts to go into details but we can provide an overview here.
Lexer
Lexer’s job is to convert a stream of characters into recognizable tokens. Token is just a pattern of characters that has some meaning in the source language. For example, word “while” is a keyword in C language so if the lexer recognizes while in a stream of characters it can identify it as while “token”. Regular expression matching is the most common technique used to recognize patterns in the stream of characters. Let’s look at a simple example. Let’s assume that our Lexer’s definition of tokens include the following rules (a subset of all possible possible token definitions)
- Any alphanumeric combination that is not a reserved language keyword is identified as identifier token and named as TOK_IDENT (it could be an enum)
- “=” symbol is identified as TOK_EQ
- “+” symbol is identified as TOK_PLUS
- “; ” symbol is identified as TOK_SEMCOL
Following diagrams shows how our Lexer will convert “X=A+1;” line of code into a stream of tokens.

Parser
Parser works in conjunction with the lexer to convert the input source language into a structured intermediate representation known as the Abstract Syntax Tree (AST). There is also an intermediate step of creating the parse tree which captures all the information from the source and then is converted to AST after removing redundant information that is not needed for downstream analysis. E.g. parenthesis in expressions. There is a lot of theory that goes into how parsers work; a topic for another post.Typically parser asks lexer for the next token(s) whenever needed. It is at the parsing stage that syntax checks are made and an error is raised if the syntax doesn’t match the syntax of the source language as defined in Language Reference Manual (LRM).
Using the same example as before, let’s explore how AST might look like. Animation below shows how the AST corresponding section (green nodes) might look like like for a top down parser (more on top down and bottom up parsers here). You can have more or less nodes as they are implementation specific but the general idea should remain the same.

Static Analyzer
Parser does basic syntax analysis and creates AST once all syntax checks are passed. Static analysis validates the AST for semantic correctness. For example, statement X=A+1; is a syntactically correct statement in C but is not semantically correct if variables X and A are not defined or if their types don’t match. Purpose of static (or semantic) analyzer is to perform all such checks that can be performed at compile time. It can also perform some basic optimizations to the AST to make it ready for the next (code generation) phase.
Code Generator
In this phase the validated AST from previous static analysis phase is used to generate the target code. In practice, there could be multiple code generation and optimization phases in a compiler pipeline. For example, most modern compilers will first generate code in some intermediate representation (IR), perform optimizations on it, generate native machine code from the optimized IR and perform another level of optimization on it.
Lets see how our example of X=A+1; will look like in the machine code. For the same of simplicity let’s just assume that we only have one code generation phase that directly generates X86 assembly code. Generated code might look like this:
movl $1, 8(%esp)
movl 8(%esp),%eax
addl %eax,$1
movl %eax, 12(%esp)
Instruction 1 is moving value of 1 to memory location of variable A, instruction 2 is moving contents of variable A to register eax, instruction 3 is adding 1 to contents of register eax and storing the result in eax, instruction 4 is copying the contents of register eax to memory location of variable Y. Don’t worry about the details of each instruction. Purpose of this example is demonstrate the concept and not to go deep into X85 assembly instruction set. Our pipeline will now look like the following
Optimizer
The raw code generated by the code generator lacks basic intelligence like eliminating unreachable code, consolidation of common subexpressions (Common Subexpression Elimination) etc. Optimizer’s job is to perform such optimizations to make the code execute faster. Notice in the previous example we are assigning an integer literal 1 to A and then adding 1 to the value of A. Optimizer might reduce 4 steps of the previous example to just one step of assigning a value of 2 to X.
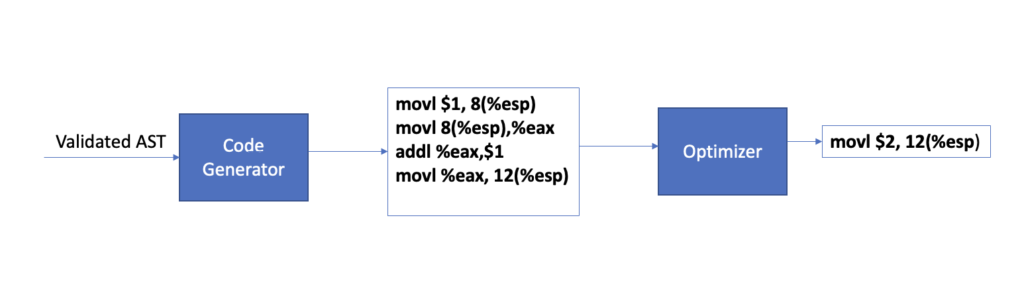
Putting it all together
Putting all of the above steps together for our example gives us:

Conclusion
This post provides an overview of end to end working of a compiler. All practical implementations will have some modifications to this pipeline for specific needs. Compiler engineers go into depths of each of these pipeline stages. But for general software engineer/programmer it is enough to know the basics of the compiler pipeline described in this post.
2 Comments
Myth of interpreted vs compiled language. · September 12, 2022 at 4:13 am
[…] into low level X86 (target) instructions. You can get high level overview of how compilers work here. The compiled code can then be executed. So there are two distinct steps needed in order to run the […]
Which Programming Language to Learn To Excel in Career · October 30, 2022 at 7:56 pm
[…] low level concepts (like memory management) and how computers understand different languages. Read this post if you are interested in learning how computers understand high level languages. Once you know […]